What Is a Local LLM? Why Local AI Matters in 2026
A practical guide to local LLMs, on-device AI, hardware requirements, privacy, and how local language models work.

In recent years, local AI has become more important as users look for better privacy, more control, and less dependence on cloud-based AI tools. At a basic level, local AI refers to models that run directly on a user’s device or inside a controlled local environment instead of relying only on remote cloud infrastructure.
This shift did not happen suddenly. It grew from practical concerns: sensitive data, constant internet dependence, cloud AI costs, and the need to use AI in workflows where users do not want every prompt sent to an external service.
A local LLM is one of the most common examples of local AI. It can help with writing, summarization, document review, coding support, and question answering while processing supported tasks closer to the user’s own device.
Tools like Sigma Browser reflect this shift by bringing downloadable local models and Private Mode directly into the browser, making local AI more accessible for private, offline-friendly, and device-based workflows.
What Is a Local LLM?
A local LLM is a large language model that runs on your own hardware. That hardware might be a laptop, desktop computer, workstation, private server, or internal company machine.
Like cloud-based language models, local LLMs can generate text, answer questions, summarize documents, assist with writing, and help process language-based tasks. The key difference is not what the model can do, but where the work happens.
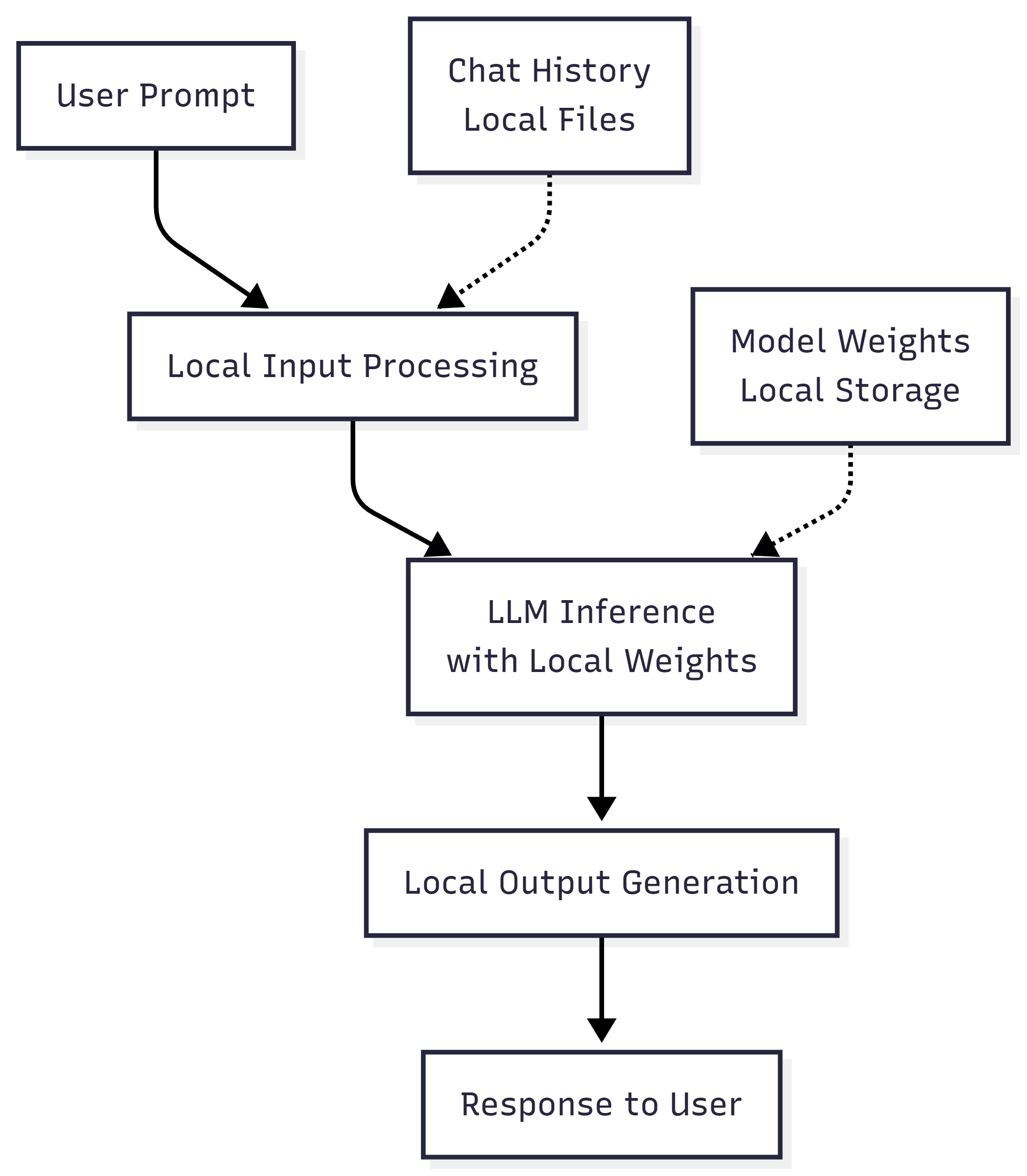
With a local LLM, inference happens locally. Inference is the process where the model takes your prompt and generates a response. In a cloud setup, that process happens on remote infrastructure. In a local setup, it happens on the device or environment where the model is installed.
.png)
How Does a Local LLM Work with User Data?
With cloud AI, prompts are usually sent to remote servers for processing. If a prompt includes private notes, business context, documents, or personal information, that data may become part of the request sent to an external AI service.
A local LLM works differently. For supported local tasks, the model processes prompts and generates responses on the user’s device or inside a controlled local environment. This can reduce data exposure because the prompt does not need to be sent to a cloud AI model for that local inference step.
This is especially useful for users who work with sensitive drafts, internal research, private documents, code, personal notes, or offline workflows. Local AI gives users more control over where processing happens and how much information leaves the device.
That does not mean local AI removes every privacy risk. Local files, browser settings, operating system permissions, extensions, backups, and connected tools still matter. The safer way to think about local LLM privacy is this: local processing can reduce external exposure, but users still need to understand their setup.
Why Run a Local LLM?
The idea of running language models locally is not new, but until recently it was largely impractical. Earlier generations of large models required substantial computational resources that were only available in data centers. Memory constraints, hardware costs, and software complexity made local execution inaccessible for most users.
Several developments changed this situation. Open-source LLM models became widely available, allowing experimentation outside closed cloud platforms. At the same time, optimization techniques such as quantization reduced the hardware requirements for inference. Consumer hardware also improved significantly, making it possible to run complex models on personal devices.
As a result, local LLMs transitioned from experimental setups to practical tools. What once required specialized infrastructure can now run on laptops and workstations, enabling new ways to use AI without relying on constant internet access or external processing.

How to Run Local LLMs in 2026
Running local large language models in 2026 requires an understanding of your hardware, because all computation happens on your own machine. Unlike cloud AI, performance, speed, and model size are limited by what your computer can handle.
Below are the four main hardware components that matter when running local LLMs, explained in practical terms.
Graphics Processing Unit (GPU)
The GPU is the most important component for running local AI models. It is responsible for performing the mathematical operations required for text generation. While CPUs can run small models, GPUs are significantly faster and are required for larger models.
VRAM refers to video memory on the GPU. It determines how large a model your system can load.
B stands for billions of parameters. More parameters generally mean a more capable model, but they also require more VRAM.
Practical guidance
- Smaller local models can run on more modest hardware, especially when optimized or quantized.
- A GPU can make generation much faster, but it is not always required for basic local AI tasks.
- More VRAM allows larger models to run more smoothly.
- Larger models and longer context windows usually need stronger GPUs and more memory.
Why this matters
If your GPU does not have enough VRAM for a selected model, the model may run slowly, fall back to system memory, or fail to load depending on the setup. For everyday users, the best approach is to start with a model that fits your device instead of chasing the largest model available.
How to check your GPU and VRAM
System Memory (RAM)
System RAM acts as your computer's general workspace. While VRAM houses the actual model, system RAM manages active data processing, background caching, and seamless multitasking during AI inference.
If you run out of RAM, the system may slow down dramatically or fail to run the model properly.
Practical guidance
- 8–16 GB RAM may be enough for lightweight local AI workflows, depending on the model and app.
- 16–32 GB RAM is more comfortable for everyday local LLM use.
- Larger models, longer context, multitasking, and developer workflows may need more memory.
- Enterprise or multi-user local AI deployments usually require much stronger hardware.
Why this matters
Even if your GPU is strong, insufficient RAM can bottleneck performance or cause crashes.
How to check your RAM
Processor Requirements
The CPU coordinates tasks, manages data flow, and supports parts of inference that are not handled by the GPU. While the CPU is not the primary bottleneck, modern instruction support and multiple cores improve overall stability and responsiveness.
Practical guidance
- A modern multi-core CPU improves stability and responsiveness.
- CPU-only inference is possible for some smaller models, but it is usually slower than GPU-assisted inference.
- Newer CPUs generally handle local AI workloads better, especially when multitasking.
- Enterprise deployments may require server-grade processors depending on scale.
Why this matters
A weak CPU can slow down loading, preprocessing, and multitasking, even with a strong GPU.
How to check your CPU
Storage Configuration
Local models are large files. Storage speed directly affects how quickly models load and how responsive the system feels.
NVMe SSDs are significantly faster than traditional HDDs or SATA SSDs and are strongly recommended.
Practical guidance
- SSD storage is strongly recommended because model files can be large.
- NVMe SSDs help models load faster, but they are not mandatory for every local AI workflow.
- Storage needs depend on how many models you keep and how large they are.
- Users who test many models may need more storage than users who keep one lightweight setup.
Why this matters
Slow storage can increase startup times and make switching between models less responsive. Faster storage helps, but the exact requirement depends on the model and workflow.
How to check your storage
Examples of Local LLM Model Families
Most local LLM setups require users to choose a model, install separate software, check hardware limits, and configure the environment manually. That can be intimidating for people who want the privacy benefits of local AI without building a technical stack from scratch.
Sigma Browser simplifies this process by providing a catalog of downloadable local models inside Private Mode. Users can review approximate RAM requirements, download a suitable model, and activate it directly in the browser. At the time of writing, the catalog includes options from families such as Qwen, Gemma, GLM, and Nemotron, although availability may change with product updates.
Once a model is activated, it can support private writing, summarization, document review, content analysis, and other supported local AI workflows. Performance still depends on the user’s device, available memory, model size, and task complexity.
Sigma also connects local models with browser-based agents. In Sigma AI Agent, users can choose OpenClaw or Hermes and select a local model in Private Mode instead of relying only on a cloud provider. This brings local model selection, browsing, and supported agent workflows into the same environment.
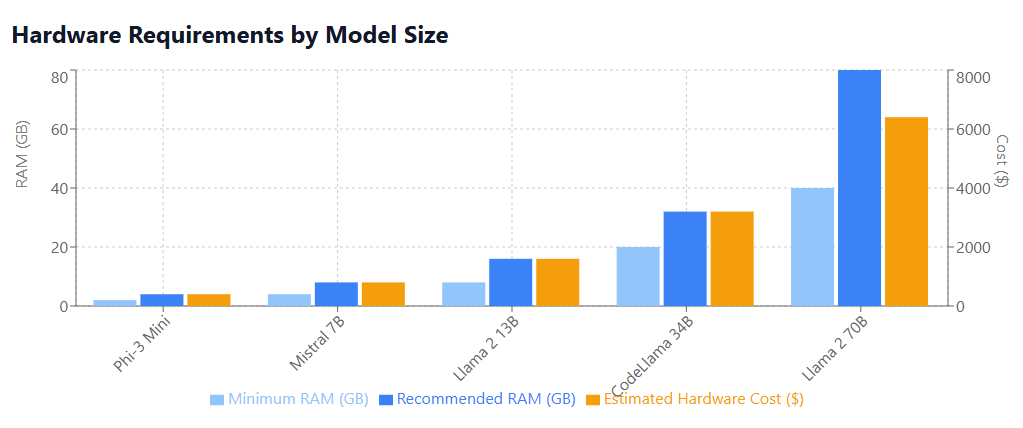
The hardware requirements for some of the LLM families are shown here:
Local AI: The Architectural Choice
Rather than treating local models as a separate technical setup, some modern tools integrate them directly into everyday applications. Sigma Browser applies this approach by letting users download and activate local models inside Private Mode, where supported prompts can be processed on the user’s device.
This can make local AI useful for everyday writing, summarization, document analysis, and other private workflows without requiring users to manage a completely separate model environment. Web search, Deep Research, connected services, and other online features may still require internet access or external processing, so users should always check which mode and provider are active.
More articles


Download Sigma Browser
Questions & Answers
reach out to us on X at @Sigma_Browser
Get Sigma on Android










