Cloud AI vs. Local AI: Exploring Data Privacy
Learn how to use local AI for encrease your privacy and why Sigma Browser is the best tool for that

AI tools are now a regular part of how we work. People use them to write messages, analyse documents, summarise web pages, and automate routine tasks. Most of the time, these tools do the job, and users usually don't think about how the results are produced or where their data actually goes. Sigma Browser is an example of a local AI system that runs entirely on a user's device, keeping prompts, context and outputs private while still providing the same types of AI assistance.
There have been a few big incidents recently that show how risky it is to rely on cloud-based AI and data services. One time, security researchers found a Chinese AI startup's database exposed on the public internet with no authentication, which meant that user chat histories, API keys, system logs and other sensitive information were accessible to anyone who discovered it. This shows how cloud storage misconfigurations can lead to broad data exposure.
Understanding where AI computation takes place helps clarify what happens to prompts, contextual information, and generated outputs. It also explains why some AI systems need constant internet access and ongoing payments, while others, like Sigma Eclipse, can operate offline and without per-request costs. This article looks at the differences between cloud AI and local AI by focusing on data flow.
In short, a comparison between Local AI and Cloud AI might look like this:
But let's take a closer look at the differences.
Private Browsing with Local AI: Where Your Prompt Goes
When you use a cloud-based AI system, the user's prompt is sent from the device to a remote server for processing. This is done over the internet and normally includes the full text of the request. Once it's processed, the response is sent back to the user's application or browser. Even if you know how to turn on private browsing in a standard browser, your data may potentially be accessed by its employees, automated monitoring systems, third-party cloud infrastructure providers, legal or regulatory authorities, and, in some cases, integrated partners or external analytics services.
With a local AI model, the prompt always stays on your device. The text is processed straight away in the system's memory by a model that's already been installed locally. You don't need to do any external communication to complete the request. This architectural shift redefines what private browsing truly means in the age of AI.
This difference is important when you're dealing with prompts that have personal or sensitive information. For example, drafting a private email, analysing an internal document, or working with account-related text all involve data that some users may not want to transmit outside their device.

What Context Is Shared With the Model
AI systems often rely on more than just the text a user types. Context can include surrounding content, such as a webpage being viewed, a document currently open, or previous interactions within the same session. In a traditional browser, knowing how to turn on private browsing is a good first step, but it often fails to stop this deeper level of data sharing.
In cloud-based AI systems, this contextual information may also be transmitted to external servers so the model can generate more relevant responses. Depending on the implementation, this can include page content, metadata, or interaction history associated with the request. Even if you are using a standard private browsing mode, the "context" of your open tabs or the PDF you are summarizing is frequently sent to the cloud provider's infrastructure for processing.

Storage, Logging, and Retention
Once a prompt has been processed, how that data is handled depends on the architecture of the AI system. When it comes to cloud-based AI, requests and responses often go through logging systems. You can use these logs for things like monitoring, debugging, stopping abuse, or making services better. This is a critical point of confusion for many: they often ask what is incognito mode and assume it stops this process. In reality, while private browsing prevents your history from being saved locally on your device, it does absolutely nothing to stop a cloud AI provider from logging your prompts on their servers.
How long providers keep this data depends on their own rules and legal obligations. Even if data isn't meant to be stored long-term, it might still be around in server memory or logs as part of the usual system operations. For the user, this means that copies of their input and output can be stored outside their device, even if only for a limited time – regardless of whether they have enabled a private browsing window.
With local AI, there's no need for server-side infrastructure when it comes to processing requests. Any prompts and contextual data will be handled entirely within the device's runtime environment. Once you've finished a task, no outside system keeps a record of the interaction unless you save the output. This means that data doesn't stick around in places outside of the current session, providing a level of security that far exceeds what a standard "incognito" tab can offer.

Internet Dependency and Control
Cloud-based AI systems require a persistent internet connection to function. Because everything's done remotely, the service depends on network access, server uptime, and external system performance. If the connection is interrupted, the AI becomes unavailable. This is a major limitation for users who rely on private browsing to protect their workflows; if the "private" session is tethered to a remote server, you are never truly disconnected from the web's tracking capabilities.
Once installed, local AI operates independently of network connectivity. You can do tasks even when you're not connected to the internet, and the system will keep going even when the device is fully offline. This gives users control over when and how the AI is used—a level of autonomy often misunderstood by those asking what incognito mode is, as that feature still requires an active internet connection to load the very tools you're using.
The internet also makes it harder to verify things. With local AI, you can check that processing is happening on-device by turning off network access and seeing that the system keeps on working. This is a useful way to check data flow assumptions without relying too much on policy statements. In Sigma, our private browsing architecture ensures that even if your Wi-Fi is on, the AI's processing remains physically gated within your hardware, providing a "digital air-gap" that no cloud service can replicate.

Cost and Data as a Resource
The way an AI system is designed also affects how much it costs to run. Cloud-based AI services usually charge you either per request or based on how long it takes to do something. Each query uses server resources, and the cost can vary depending on the provider and how much you use it. If you use the system a lot, these costs can rack up fast, and you'll need to keep an eye on how it's being used.
Many users seeking to lower these costs often ask what is incognito mode or try to find private browsing workarounds, but neither of those tools addresses the underlying expense of cloud API tokens or subscription fees. While standard browsers try to convince you that their incognito mode is really private, they are only referring to your local history; they still profit from your data and charge you for their AI services.
Local AI, on the other hand, runs completely on the user's device, using whatever computing power it's got. There's no extra charge for using the local model. The main things holding it back are the device's processing power and memory, not external service costs. This means users can run tasks without worrying about usage limits or extra charges, making local AI easy to predict financially and operationally.

Try Local AI for Real Private Browsing
The algorithm for both models can be illustrated using the following scheme:
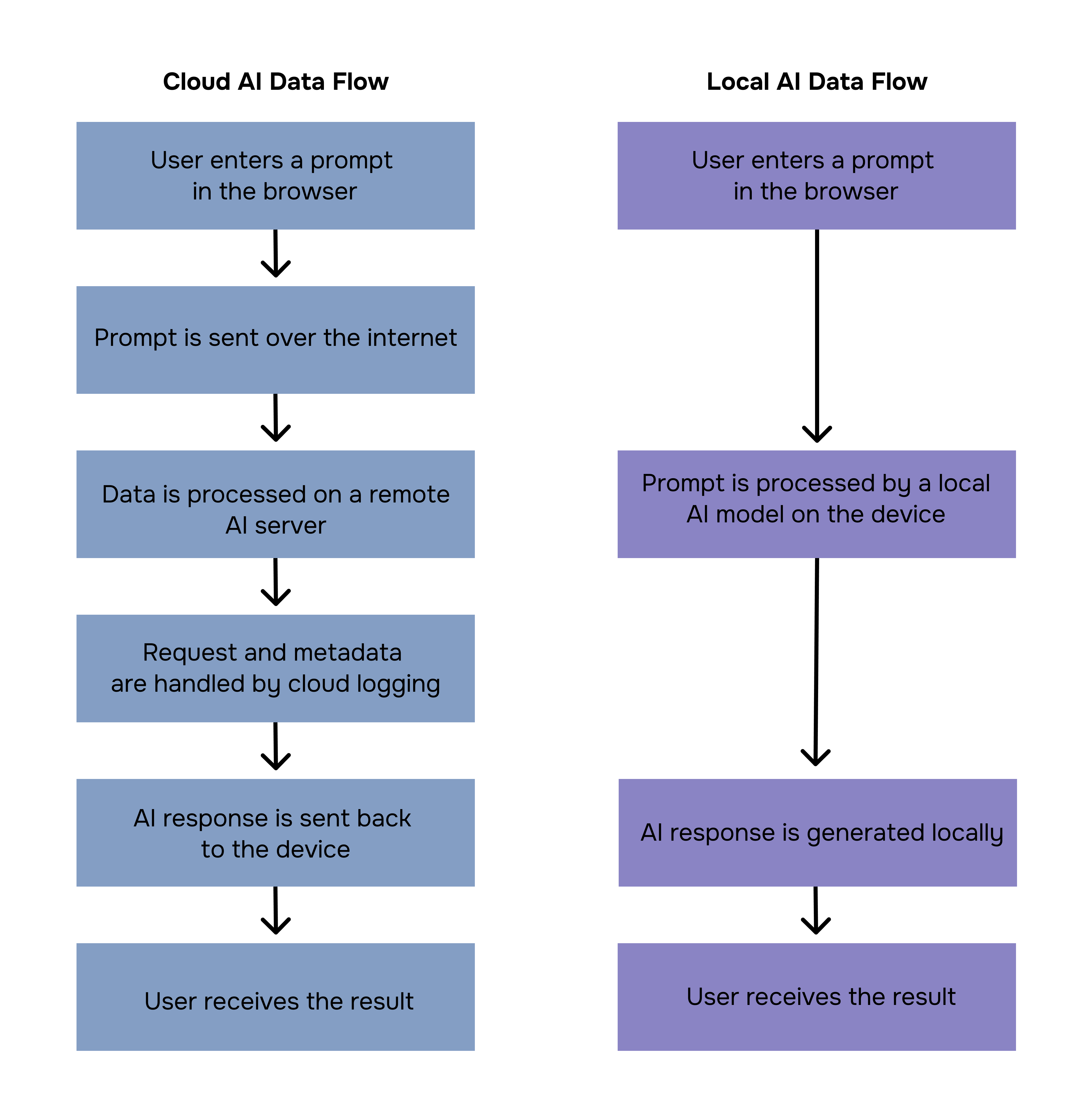
The main difference between cloud and local AI is where computation occurs and, as a result, where data flows. Local AI, like Sigma, handles all processing on the user's device, giving them total control over their data. You can enable local LLM mode (Eclipse) in Sigma Browser to make sure that AI tasks are done locally.
With Sigma, you can get the best of both worlds, combining autonomy, privacy and convenience. While cloud AI is still better for really big computations or services that need a lot of external integration, Sigma shows that local AI can handle daily tasks efficiently while keeping all data on the device. Knowing the differences between them helps users decide which AI architecture is best for them and meets their privacy needs.
More articles













